
El pasado día 6 de marzo, la empresa francesa Mistral AI lanzaba un LLM destinado a labores de OCR. Para los neófitos en esta materia, la tecnología OCR (Reconocimiento Óptico de Caracteres, por sus siglas en inglés) convierte imágenes o documentos escaneados en texto editable. Básicamente, permite que un ordenador reconozca letras y números en fotos o documentos impresos, facilitando copiar, editar o buscar información sin tener que escribirla manualmente.
Tradicionalmente se ha recurrido a redes neuronales convolucionales (CNN) para estas labores. Proyectos más recientes, como Tesseract 4.0 de Google, habían combinado redes convolucionales para la extracción de caracteres con redes neuronales recurrentes (RNN) para estructurar la secuencia de caracteres y palabras. Sin embargo, con la llegada de la arquitectura transformer, esta tecnología está ante un aumento de capacidades al ser capaz de entender y procesar cada elemento de los documentos (texto, imágenes, tablas, ecuaciones…), abriendo ante sí un campo muy amplio de posibilidades.
Mistral OCR vs SOTA
Tomando como referencia la propia nota de prensa de la empresa gala, el nuevo modelo Mistral OCR 2503 se situaría como el nuevo modelo SOTA (State Of The Art, término en inglés que se refiere a los modelos más avanzados) en OCR, con una precisión general del 94,89%, frente a otras alternativas como los modelos Flash de Gemini o GPT 4o, que se situarían en torno al 90%. Aunque esta diferencia puede parecer insignificante, Mistral AI afirma que, al extraer también imágenes junto con el texto, no solo es más preciso en la extracción textual, sino que además aporta esta funcionalidad de la que el resto no dispone.
Gracias a su arquitectura transformer, todos estos modelos destacan por su capacidad para entender contextos, diferentes idiomas y tipos de objetos, categorías en las que Mistral OCR también reporta ligeras mejoras respecto a otros modelos SOTA. Otra gran ventaja de esta arquitectura es que permite dar instrucciones mediante prompts para focalizarse en determinados aspectos al extraer información y formatear los resultados en JSON personalizados.
Uno de los puntos fuertes de este Mistral OCR es que se trata de un modelo extremadamente eficiente, capaz de procesar hasta 2000 páginas por minuto con un coste de 1 dólar por cada 1000 páginas procesadas.
Por su parte, Mistral AI ofrece varias soluciones para los clientes, ya sea consumiendo el servicio a través de su API, mediante un proveedor cloud o alojado localmente. En las opciones no locales, los datos se almacenan en la Unión Europea, aspecto relevante para cumplir con la normativa europea de protección de datos.
Lo pongo a prueba
He puesto a prueba el modelo con documentos que presentaban ciertas estructuras complejas como la división en columnas, tablas con filas concatenadas, integración de imágenes entre el texto, gráficos y tablas incrustadas… Dado que para usos empresariales tiene especial interés la extracción de información desde reportes en formato PDF, he centrado la prueba en estos documentos, aunque el modelo también soporta perfectamente otros casos, como la extracción de texto manuscrito o desde fotografías de documentos.
En términos generales, en documentos sencillos, los resultados son increíbles. Si bien es cierto que la API de vez en cuando arroja un error de servidor, procesa los documentos con una rapidez asombrosa. Al igual que el resto de modelos, son muy precisos en el texto. La sensación que me produce es que no llega a esos niveles cercanos al 100% que arrojan los benchmarks, especialmente en pies de páginas y elementos de tablas, pero en el cuerpo del texto es muy consistente.
El resultado de la extracción se devuelve en formato Markdown, especialmente útil para almacenamiento vectorial y para el procesamiento y consumo posterior por modelos LLM. Sin embargo, este enfoque presenta limitaciones en cuanto al formato, especialmente en tablas complejas, que en escenarios avanzados no logran reflejar correctamente la estructura original. Por otra parte, el hecho de que procese los documentos por páginas resulta especialmente útil para gestionar metadatos en esquemas que utilizan RAGs, pero genera ciertos errores de cohesión en el documento. Por ejemplo, en algunos saltos de página se produce un corte abrupto de oraciones, lo que puede generar fragmentos incoherentes y pérdida de información.
Imagen 1 - Caso de salto de página en un artículo con 2 columnas (Original)
 Imagen 1 - Caso de salto de página en un artículo con 2 columnas (Resultado)
Imagen 1 - Caso de salto de página en un artículo con 2 columnas (Resultado)
En escenarios de textos distribuidos en columnas, normalmente también acierta en el orden y sabe concatenar el texto cuando se extiende entre columnas, siendo muy preciso en este aspecto. En cuanto a la extracción de gráficos e integración de textos, de nuevo, en formatos sencillos, es capaz de recuperar entender cuándo es una imagen relevante, extraerla e incorporarla en el resultado.
Imagen 2 - Gráficos (Original)
Imagen 2 - Gráficos (Resultado)
No obstante, con grafismos o páginas muy cargadas de elementos visuales, se desorienta con cierta facilidad y hace extracciones extrañas o de elementos irrelevantes:
Imagen 3 - Gráfismos y páginas cargadas de elementos visuales (Original)
Imagen 3 - Gráfismos y páginas cargadas de elementos visuales (Resultado)
Imagen 4 - Gráfismos y páginas cargadas de elementos visuales (Original)

Imagen 4 - Gráfismos y páginas cargadas de elementos visuales (Resultado)

También tiene bastantes problemas a la hora de comprender saltos de línea, pero que se hacen por extensión de la columna y que deberían ir dentro de la misma celda en una tabla, así como con celdas concatenadas y estructuras jerarquizadas:
Imagen 5 - Celdas concatenadas y estructuras jerarquizadas (Original)
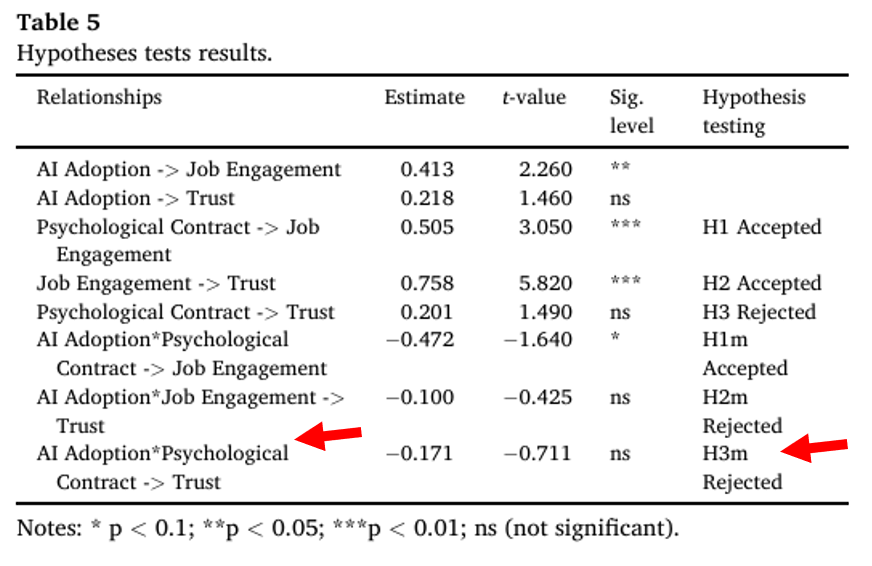
Imagen 5 - Celdas concatenadas y estructuras jerarquizadas (Resultado)
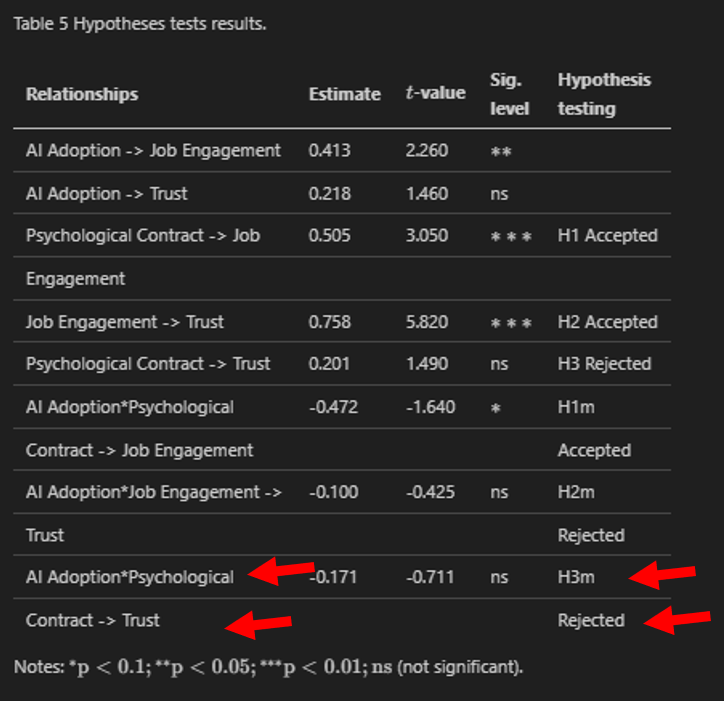
Imagen 6 - Celdas concatenadas y estructuras jerarquizadas (Original)

Imagen 6 - Celdas concatenadas y estructuras jerarquizadas (Resultado)
En cuanto a formulación, superíndices, subíndices y otros formatos de estructura, es capaz de hacer una buena interpretación de manera consistente.
Imagen 7 - Formulación, superíndices, subíndices y otros formatos (Original)

Imagen 7 - Formulación, superíndices, subíndices y otros formatos (Resultado)

Conclusiones preliminares
En líneas generales, se trata de un modelo muy bueno. Quizás la gran noticia sea que haya sido desarrollado por Mistral, una empresa europea comprometida con la comunidad open source. Espero que este lanzamiento sea precursor de una versión abierta para la comunidad y que, con modelos de tamaño contenido (por debajo de los 7B de parámetros), pueda ejecutarse en dispositivos domésticos y ser más accesible para implantaciones locales en empresas, garantizando así la completa privacidad de sus datos.
Todavía hoy, en un mundo digitalizado y altamente expuesto a la web y a la interoperabilidad, gran parte de la información sigue estando en documentos no estructurados o semiestructurados, difíciles de interpretar para las máquinas. Este tipo de tecnologías constituyen piezas clave para la automatización, la interoperabilidad y los procesos de implantación de inteligencia artificial y explotación de datos en las empresas, al situarse en la base misma del esquema.
Aunque las soluciones existentes ya ofrecían un elevado grado de fiabilidad en la extracción de texto, la integración con otros elementos del documento y la facilidad de uso de esta solución abren nuevas posibilidades, especialmente considerando el potencial que estos avances pueden aportar a sistemas de agentes basados en RAGs o modelos con fine-tuning. El uso de elementos visuales más allá del texto no es tan novedoso como se pretende transmitir, ya que Anthropic introdujo mejoras similares en su modelo Claude Sonnet 3.5 en noviembre de 2024. Sin embargo, dicho sistema no es abierto ni accesible, a diferencia de esta herramienta, que permite realizar extracciones para uso particular.
Además, su precio accesible y su velocidad permiten su aplicación en sectores donde anteriormente no se consideraba viable debido a los costes o requisitos operativos, tal como ocurrió en su día con familias de modelos más pequeños como los Mini de OpenAI, los Flash de Google, Haiku de Anthropic o las versiones con menos parámetros y cuantizadas de Llama, Qwen y otros modelos open source.
Aunque presenta ciertas limitaciones que seguramente se irán puliendo en el futuro, es una herramienta útil y, en cierto modo, está justificado el entusiasmo que está generando en la comunidad.